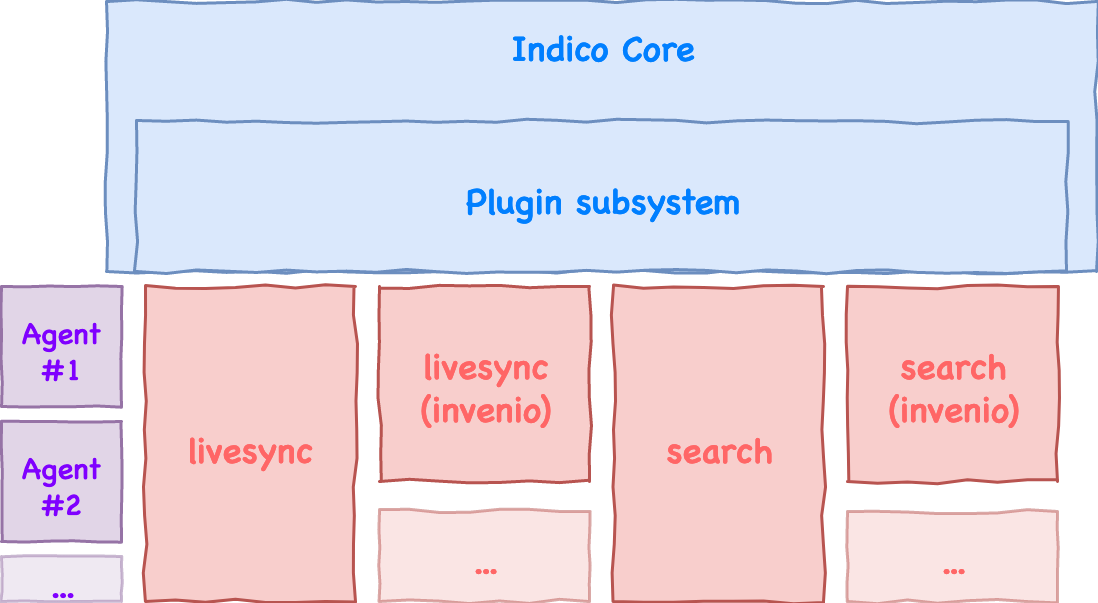
The current branch of Indico has moved the “search” action from a core function to a plugin framework. As @pferreir kindly explained via email:
The search box will be present as long as you have a search plugin
present. The indico-plugins repository includes a search plugin that can
be used with Invenio:
However, due to the sheer amount of changes both in Indico and Invenio
in the last couple of years, I’m afraid it will probably not work in
most modern setups. We also have open sourced the plugin that we use
internally (with Sharepoint Search, which is what is currently used at
CERN):
It’s not something you can reuse out of the box, but it gives you an
idea of the internal structure of a search plugin.
This is for the actual search interface, but there is a 2nd part, which
is what pushes changes that happen in Indico to the search server, so
that it indexes them. That’s what we call “livesync”, and there are
livesync plugins for those two options too.
Unfortunately, there isn’t yet a community-friendly option that you can
use out of the box. That may change soon, since we’ll be going back to
using Invenio, which is now based on Elasticsearch. When we do so, we’ll
publish clear guidelines on how to set up an Indico-Invenio solution.
As I mentioned in my answer to your question, it may be interesting to
check for other interested parties in the community (e.g. through the
forum). I am sure others feel the same need and if a few interested
parties join forces together, the community could probably find a
solution that is beneficial to all. We’d be glad to take part in that
discussion and help it come to fruition (although the manpower we can
dedicate to that right now is very limited)
Has anyone done some work on search that they’re willing to share, or would like to contribute to a group effort?
Please allow me to correct: search has never been a core function. Indico never included a built-in search engine and, as far as I can remember, at least since 0.9x search was always provided via a plugin.
If anyone is interested in collaborating, or if some site has already deployed a search plugin on the current version of Indico, perhaps they could share their experience?
At FNAL we are interested too in the development of a search plugin suitable for elastic search.
We have already setup an elastic search and using it with a different application.
As soon as we start looking into the indico search plugin in the next couple of weeks, I am sure that we will have a lot of questions.
The following is an daft outline of the Indico Elasticsearch plugins of the FNAL - BNL collaboration
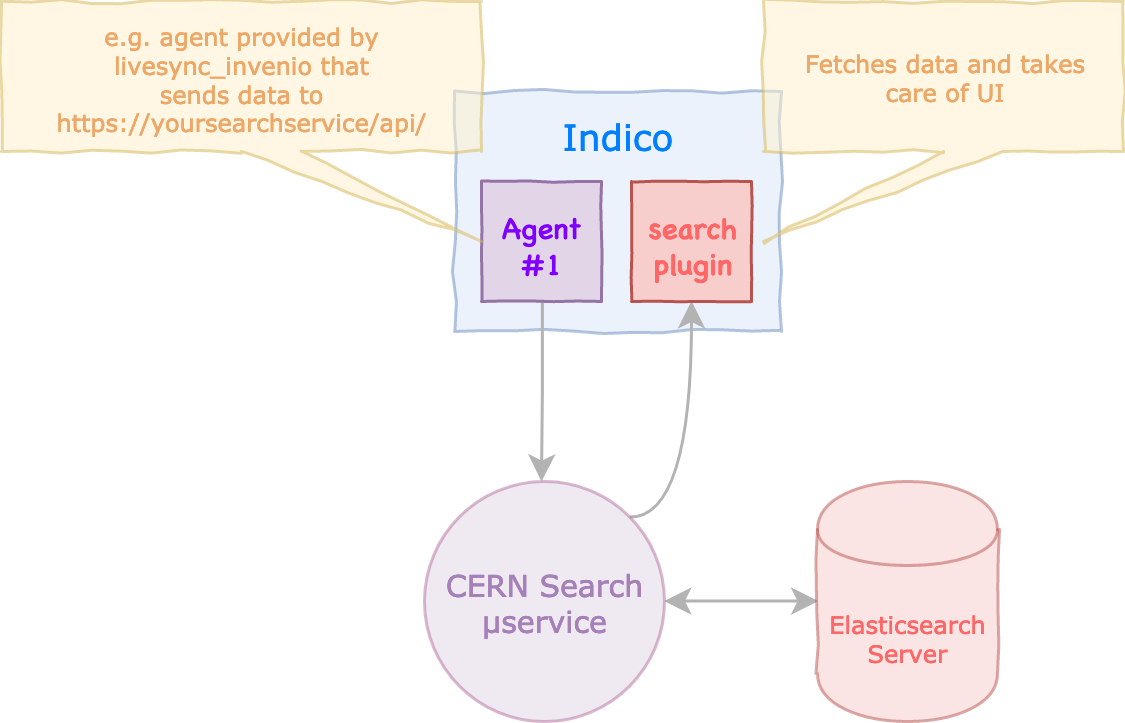
The implementation requires two sets of plugins: one set to push the search metadata to the search engine (livesync, livesync_elastic) and another set for sending the search string and receiving/displaying the search results (search, search_elastic)
The Indico search data will be pushed to the search engine, and they will contain along with the search metadata (that includes URLs for full text search by the search engine), authorization information (in the form of the user’s email or group name) so that the search engine will return results only authorized for that user. The authorization information will be part of the search engine’s data.
The Indico Elasticsearch plugins will use the same mechanism CERN is using: for pushing the data to the search engine it will use the general livesync plugin (as is) and a modified version of the livesync_cern plugin. The data will be pushed to the search engine using the Elasticsearch’s URL. Also, the same data could be pushed to more than one URLs if needed.
As Elasticsearch reads only data in JSON format, the data that is provided by livesync_cern are in MARCXML format need to be converted to JSON. After discussing with the CERN Indico team, it will be easy enough to write the appropriate python code to create the JSON output, so that will be part of Indico.
Indico uses only certain MARC tags which are described in CERN’s legacy docs: https://getIndico.io/legacy-docs/wiki/Dev/Technical/MARCXML.html
For returning only authorized results we will take into account the Elasticsearch’s capability of indexing a field along with each document containing a list of users or groups and then filter search results based on that field. If requests to Elasticsearch are only being made by Indico and the indices won’t be exposed for direct access, this will suffice. We also need to have in mind that Elasticsearch itself does not provide any security without a licensed plugin.
The search plugins will read the user’s input and send it along with the user’s email (if logged in) to the search engine and then receive the search results and display them appropriately. The results will be received the way the Elasticsearch creates them. We will try to explore to paginate the results by including offset and limit parameters in the query. We will maintain the current way of categorizing search results as events, contributions, files or other categories that might seem appropriate. This will be investigated later in the project.
CERN is moving to a new search solution that will integrate Indico with Elasticsearch through Invenio (Invenio 3 is much more lightweight than its predecessor and uses Elasticsearch). This is the solution they have adopted for CERN’s new search engine and Indico will have to adopt it. The code is publicly available here:
I’m Pablo, the main developer of the above mentioned new “CERN Search” platform. I just wanted to address a few questions in case they might help you.
Could the JSON files that we will create be used by Invenio, provided that we provide Invenio’s URL and the ES schema(s) are the same as the ones expected by Invenio?
The JSON schemas expected by the (CERN) Search instance can be modified according to your needs, and then be made to match an Elasticsearch schema. Later on, the properties of this ES schema can (should) be modify to achieve optimal search results.
In the repository there are a couple of preliminary JSON and ES Indico schemas we made time ago. However, this are not final and can (or should) be modified to better suit.
This means, yes, it is fully customizable. It can even be customized per Search instance, not all instances have to use the same schemas.
What will be the major difference (if any) between using just ES (our current version is 5.6) and Invenio 3.0?
NOTE: This week we are planning to upgrade to ES6, because it makes much easier to work with binary files.
The (CERN) Search platform:
Provides a RESTful API, which helps decouple the webUI from the backend.
Abstracts many of the burdens of dealing with Elasticsearch (e.g.creating, deleting, reindexing, etc.) by using simple HTTP actions over different endpoints.
Provides both relational (for history and versioning of documents) and non-relational (Elasticsearch, for search) storage.
Provides means of access control per documents, which otherwise would need to be implemented (or pay a commercial ES plugin).
Handles automatically the binary files (PDF, pptx, etc.) text extraction by using Apache Tika OCR (Via an Elasticsearch plugin), just needs to receive a file as a Bytes Stream or Base64 encoded. [This part is new an not up-to-date in the documentation, it will be shortly]
Provide means of deploying it (Except for the DB and Elasticsearch, but could be also done) via Dockerfiles and also OpenShift templates.
It is based in Invenio, which means using Flask. Therefore, customizations are easy to integrate using Python blueprints. For example, change the authentication method from CERN SSO to other based on OAuth or many others supported by Invenio.
Lastly, we use it at CERN which means there will be always someone to maintain it. Same for the base framework (Invenio), so I think it is safe to say its not going to be left behind.
Finally, I want to mention that our final goal is to provide an OpenSource search platform based on Elasticsearch that can be used by any platform. This means we are open and looking forward to collaborate, it is not a tight solution. If there are modifications that need to be carried out in order to make it more suitable for Indico instances, they are welcome and we can discuss any time.
Please let me know if you have any other questions (You can also reach me via Gitter @ppanero, via e-mail ppanero@cern.ch).
In order to help everyone better understand how Indico’s livesync and search plugins are supposed to work, I made a couple of diagrams that I hope will clarify things.
Taking into account the CERN goals for the Elasticsearch, I would like to propose the following implementation:
Elasticsearch allows for _bulk operations, which resemble the existing way the livesync_cern is using to create the marcxml code. To implement the livesync_elastic plugin, I have identified the following code changes/additions:
indico-plugins/livesync_elastic - New plugin based on livesync_cern.
indico-plugins/livesync_elastic/indico_livesync_elastic/uploader.py - Add the Elasticsearch JSON uploader
indico-plugins/livesync_elastic/indico_livesync_eolastic/jsonGen.py - New file to handle the JSON string generation
The UI should be similar to the livesync_cern. The URL should be the URL of the Elasticsearch indico index, e.g. https:///indico
Since the implementation is to be generic, it will use the Elasticsearch’s REST API for communications (not the python elasticsearch package).
The plugin will, also, have the capability of initializing the Elasticsearch mappings.
As a starting point I have cloned the CERN repositories at: https://github.com/penelopec. Any new code will be under the branch Elasticsearch
Please add that in the Elasticsearch plugin, it has nothing to do with the livesync core.
Please do not use these files as an example!!!
The code in there is ancient legacy code that is FAR from being a good example.
Also, I think the json serialization should be in the elasticsearch plugin as well since the schemas (it should use marshmallow like we mentioned during the video conference) are somewhat tied to it. We can always move it up later if they turn out to be useful for something else.
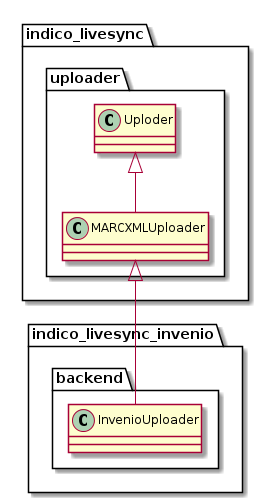
you may notice some sort of asymmetry.
For the existing invenio plugin, the code that manage the internal format code (MARCXML) in in the base package, while for the new ElasticSearch plugin, the JSONUploader will be in the plugin package instead.
Is this correct?
Not sure if there’s much benefit in splitting “JSON” and “Elastic” there. If you want to separate the JSON serialization from the actual uploading (which is probably a good idea) then I’d just add a bunch of “util” functions that do the JSON serialization and call those from within the uploader.
For example, jsonify_event(event) could return you the JSON data needed for that particular event.
Agreed with @ThiefMaster. In any case, the MARCXMLUploader made sense as a separate thing just because it was complex. Serializing to JSON is just much simpler, I believe it should be up to the plugin to define which fields are used and what are their names, and then just pass it on to a general-purpose JSON serialization function (e.g. flask.json).
When using Marshmallow, you can actually use some_schema.dump() to get a dict that can be jsonified (great if you want to pass it to someone that takes care of jsonification for you), or .dumps() to get the actual JSON string (if e.g. the requests library requires an already-serialized json string).
quick question about Marshmallow. In the INDICO devel installation I have from last year, the version is 2.x
My understand is that Marshmallow 3.x is a little bit different.
Do you plan on updating it soon? Or we are safe writing code for version 2?