Yes, we updated to v3 in master:
I have a simple question about using marshmallow:
Do I need to define new schemas to be used in this plugin for the events, contributions, etc. based on mm.ModelSchema or am I missing something more fundamental?
Yes, define a schema based on mm.ModelSchema but specify which fields you actually want to include. For anything that has different names or needs extra logic you still need to define Fields directly on the schema.
See e.g. the AbstractSchema in the Indico core for an example.
Great! This is what I started doing when I had second thoughts.
Thank you!
question for the developers.
I have tried to install the search_invenio plugin, as it is, in our testbed host.
-
I had to remove the Requirement “indico>=2.2.dev0” from setup.py, as our installation is 2.1.7
-
because of that, I included ‘–ignore-unclean’ in the build-wheel.py command
-
I followed the instructions, built the wheel, and pip installed it
-
then I added ‘search’ and ‘search_invenio’ to file /opt/indico/etc/indico.conf
-
and restarted the service via
systemctl stop indico-celery systemctl start indico-celery
Am I missing something? After restarting, I expected to see the searching box at the top-right corner of the page, but still missing?
Must we update indico to version 2.2?
Or is there any other service I need to restart other than indico-celery?
In the admin view, I see other plugins, but not search or search_invenio. Should they be there?
The last line, after reinstall, in the log file looks like this:
GET / [IP=666.666.666.666] [PID=4395] [UID=None]
thanks a lot in advance.
Yeah, that’s OK if your plugin is compatible with 2.1 - in that case you can safely require indico>=2.1 instead.
It sounds like you didn’t restart uwsgi! Celery is only used for background tasks, but indico itself is running in uwsgi, so you need to start that one.
Aha!
Now I am making some progress, so to speak
Internal Server Error
But at least that means it notices the changes, for good or for bad 
BTW, how do I know if a plugin is compatible or not with the installed version of INDICO? Must the version numbers match?
it’s compatible if it’s not using anything that was only added in a later version. for example, if you’re using anything related to webpack (e.g. inject_bundle), you need 2.2+.
Version numbers don’t really matter there, but a plugin that requires 2.2+ should of courses specify that in its setup.py
OK. Re-building, and re-installing, plugins “search” and “search_invenio” from tags/v2.0.1 instead of master works.
I have a first very primitive version of the livesync_elastic plugin.
URL: https://github.com/penelopec/indico-plugins/tree/Elasticsearch/livesync_elastic
I would appreciate comments about this implementation as well as some help with the marshmallow schemas.
For the implementation (following the guidelines of livesync_cern) I have added code in the following files of livesync (URL: https://github.com/penelopec/indico-plugins/tree/master/livesync/indico_livesync ).
Question: Is this correct?
- __init__.py and
- uploader.py
The implementation of livesync_elastic makes the following assumptions:
- Only two operations are used:
- index - for creating new document entries and updating existing ones
- delete - for deleting a document
- The Elasticsearch mapping document ID is the same as the indico obj.id
- The generated JSON string (using the defined marshallow schema) is for Elasticsearch bulk operations.
- Uses requests.post to send the data={‘json’: jsonData} to Elasticsearch (jsonData is a string)
Given the above assumptions the jsonGen.py is fairly simple.
Looking at the livesync_cern, there is code for getting the categories. Is this needed for this implementation? I know that one of the mappings is the category path which is a list of strings.
Thank you
Hi again,
now that I have under control the deployment of testing code, and everything else, I am ready to start working on the Searching plugin for ElasticSearch.
Before I do anything, I would like to get confirmation on the basics about it.
I had a look to the existing (old?) search_invenio architecture:
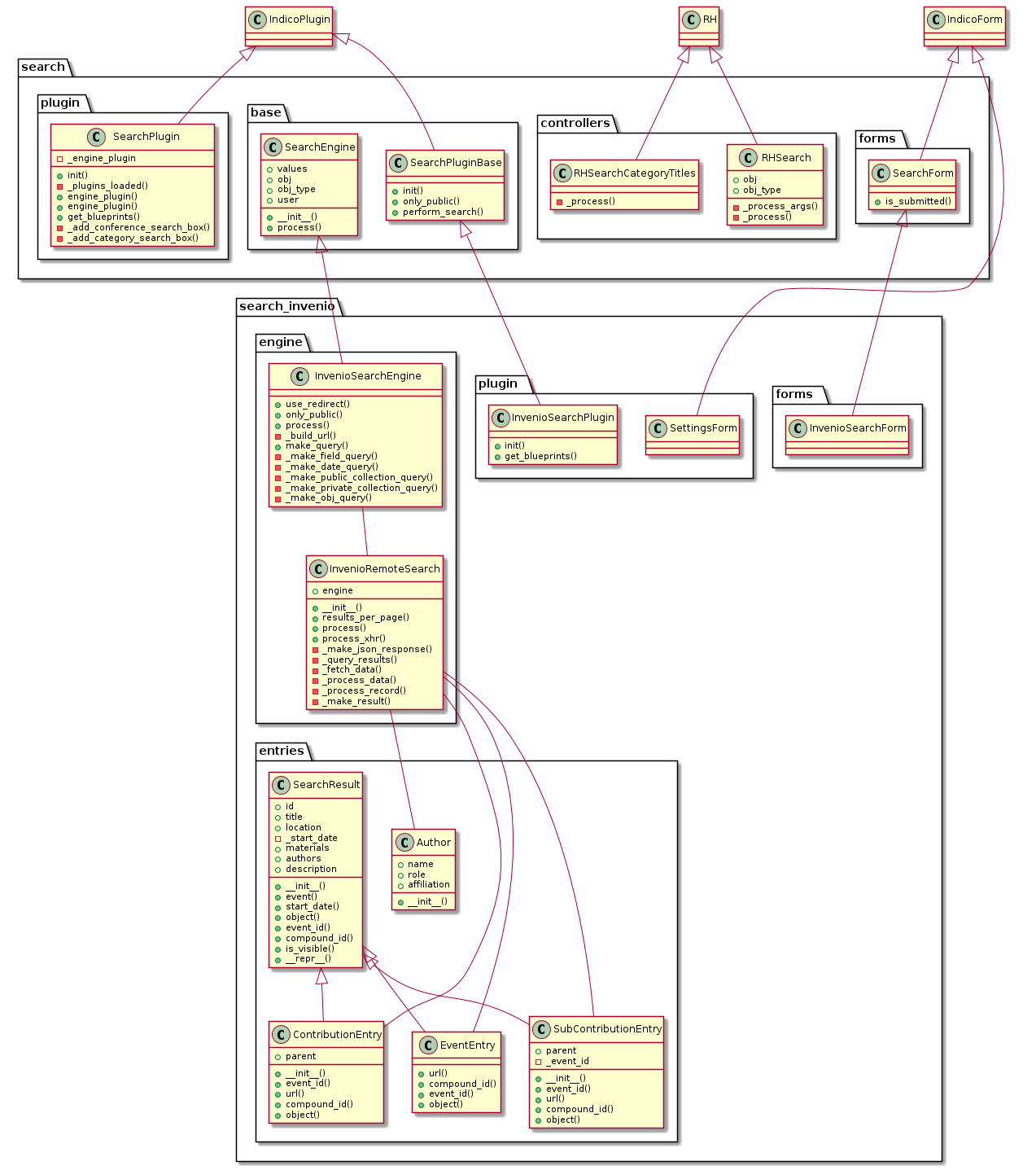
I believe that, like other plugins in INDICO, the generic stuff goes in the base classes, and only the specific details go to the plugin. Correct?
In our case, I would assume that the rendering, pagination, etc. is generic, implemented in search/ package. And we only need to take care of writing the code to query ElasticSearch (and Invenio after that) in the plugin, change the data format if needed, and that’s it. The result should be the same. Am I right?
I will be posting more questions in the next days as I go deeper into this.
thanks a lot in advance,
Jose
You cannot import anything from the livesync_elastic plugin in the base livesync plugin (remember, the latter may be installed without the former). However, like I mentioned a few times before: You do not need to follow the structure of those rather old plugins!
I think the best option is to try to keep everything in the livesync_elastic plugin - we can always refactor later if necessary. Of course, if any of the APIs in the livesync plugin need to be changed then it’s OK, but best to discuss here in case there’s a better option.
Regarding pagination etc. in the search plugin: Just like what I recommended to @penelopec above, I’d suggest you (@jcaballe) to also try keeping as much as possible in your new search_elastic plugin. Because again, we can refactor later if needed, and it’ll keep things easier if you just keep anything specific to your implementation in your own plugin. Same as above though: If any APIs provided by the base search plugin are doing something wrong or need to be changed for your plugin to work properly, feel free to - but same here, best to discuss details before!
PS: Please don’t use camelCase in filenames or variable/function names - this is not our current style anymore (we use the python defaults which are snake_case for variables/functions/files, and UpperCamelCase for class names). Also, please inherit your classes (that do not inherit from any existing class) from object; otherwise you have “old-style” classes which are generally something you want to avoid.
Since, livesync needs to remain independent of the livesync_elastic (or any other similar plugin), then it needs a more general approach for interfacing with these livesync_xxx plugins. Currently it uses the the livesync_cern model. This explains why the marcxml.py is part of livesync and it is not under lilvesync_cern.
I am not sure that I have the expertise to generalize the livesync. I’ll try to do so and you can correct what I do.
@ThiefMaster you mentioned that we should not use camelCase etc. Where can we find information about your coding standards?
Also, existing code (in the indico core, the newer the better).
The only major difference is that we use up to 120 chars per line instead of the 79 PEP8 suggests…
Hi @ThiefMaster, I believe both @penelopec and I are trying the same thing, to reuse as much as possible from the existing architecture, so we need to write the minimum amount of code in the plugins. Right?
Hence my question, which can be rephrase as “how responsibilities are split between the search/ package and the plugin”. I am not interested in re-engineering any aspect of the visualization (rendering, pagination, etc), quite the opposite, I want to reuse whatever exists as it is, if possible. So I just wanted a confirmation that the plugin only need to implement the query and deliver the result to base class.
I have now another question that may be relevant. We are using a testbed instance of INDICO with version 2.1.7 installed. I believe the latest version pip-installable is 2.1.8. However, it looks like you are working on INDICO 3. Is that right? So I am wondering if there are fundamental differences between 2.x and 3.x that we should be aware of. I don’t want to invest time working on something that will be declared obsolete in a few months
Which version we should use for development and testing?
How can we debug our plugin code? Is there a way to get more information in the log file other than just a plain “Internal Server Error” displayed on the browser?
On your local dev server with debug mode enabled you should see detailed tracebacks if something goes wrong.
In a production setup the error is usually still logged unless it breaks very early (e.g. while initializing) - if you really get just “Internal server error” without any styling etc, then you’ll have to enable the uwsgi log file to see why initializing the app fails. Or you can just use indico shell; most likely it will also fail, and there you always get a detailed error.
we are using a production setup
Generally you should first test your code on a dev setup (ie locally) before running it in the production (or production-like) environment. Debugging in a production environment is much more complicated in any case…