Still sounds useless to me (same for contribution creation date tbh - how is it relevant when something that’s generally created by a manager while setting up the event was created and thus not really relevant data for anyone just viewing the event, or searching for it).
Pablo’s docs explain which endpoint to call: http://cernsearchdocs.web.cern.ch/cernsearchdocs/usage/operations/
The base URL should be something like https://localhost:8080/api/, if your running docker locally.
I agree with @ThiefMaster. In this case we need to update the Elasticsearch mappings to not include these fields for the contributions and subcontributions.
This is great, as my schema for ES (CERN-search) is complete!
I did look at the CERN search app documentation. I guess I did not explain correctly my question:
livesync data does NOT differentiate between new objects and updated ones, only a deleted object is flagged as such.
The CERN search app differentiates between the two cases. Would livesync needs to be changed to provide this information? I know that ES can perform create or update using the index operation. Can the CERN search app provide this?
The next issue is that the CERN search app will set the ES record ID, so upon creation of a record no object ID is provided. In order to update or delete an object, how do I retrieve this ID to place it on the URL? or the URL ID is that of the object as stored in the indico tables and included in its mapping?
Looking at the example code http://cernsearchdocs.web.cern.ch/cernsearchdocs/example/ for python, I do not see where the insert or the patch operations are specified. Are they part of the URL?
How do I specify which mapping’s data to update (events, contributions, etc.)?
Also, I assume that the CERN search app accepts only one object at a time.
Livesync does keep track of updated objects. It’s just the MARCXML backend that then interprets “updates” and “creates” as being the same (kind of an UPSERT). So, I believe that work is already done.
If I recall correctly my first discussions with Pablo ~1 year ago, the idea was to use 1-to-1 correspondence of IDs, since anyway all Indico IDs are numbers.
Looking at the example code http://cernsearchdocs.web.cern.ch/cernsearchdocs/example/ for python, I do not see where the
insertor thepatchoperations are specified. Are they part of the URL?
In a REST API, they would normally be mapped to POST (or PUT) and DELETE. Maybe that’s the case?
Also, I assume that the CERN search app accepts only one object at a time.
I believe that’s the case right now.
Great! I need to find how to get this information from livesync.
I was under the impression that the CERN search app would create doc IDs that are more elaborate and different than the indico object ID. Being the same solves this issue.
So, requests.post will create a new doc, requests.put will update and requests.delete will delete a doc (requests.get do the search)
As far as what mapping it will access, I need to add the ‘$schema’ field in the json data (which could be added to the marshmallow schemas of the plugin)
"$schema": "http://<host:port>/schemas/<search_instance>/<index_doc_type>.json"
I assume that the <host:port> and the rest of the <...> are part the ES configuration.
Should these entries be part of the plugin setup page?
Hi developers,
after a while, I am resuming work 
I have a few questions related the search_json plugin:
-
I have removed “display_mode” from the settings form for the JSON Search plugin. Is that OK?
My understanding is that now, as we build the output HTML ourselves, there is no point on choosing “iframe” vs “redirect”. Correct? Or that field is still needed for something else? -
The CERN Search “endpoint” for the search_json plugin must be the same as for the livesync_json plugin. For example, from documentation, endpoint = “/api/records/”. Is there a way to ensure it is the same for both plugins?
For now, it is just a string hardcoded in both of them. Should it be part of the plugins settings, leaving to the admin to make sure it is the same in both plugins? -
What should be the behavior if, for some reason, querying CERN Search fails?
For example, if the service is down. -
Must I use flask_marshmallow and/or indico/core/marshmallow?
I have started by writing my own entry classes (similar to search_invenio/entries.py) and their corresponding Schema classes for marshmallow. Is that OK? Or should I reuse some existing INDICO code that already does that?
That’s all for today. I may have more questions as I make progress.
Cheers,
Jose
Yes, that should go away since it’s indeed not needed in the new plugin.
I disagree here. While in most cases you do want the same value, I could imagine someone using some kind of clustered setup where data is sent to a single instance X, but search requests go to load balancer Y. So I don’t see any reasons against having the settings in two places.
Just fail. Either let the exception that’s triggered propagate up (causing the default “something went wrong” message with the option to report the error, and it being automatically logged to sentry if enabled in any case) or catch it and show a nicer message. But I think the former is fine, since the service should rarely be down.
Not sure I fully understand your question - I don’t think there’s much benefit in reusing schema from the core, since you are dealing with search data here and not necessarily the actual database objects. And when you do load data from the DB, you’ll just use the ID anyway - and when you pass the resulting data to the template, you have objects that are already fine for using them; no need to serialize to dicts using a schema there (that’d only be needed if it was API-based, e.g. with a React frontend).
Quick comment on the last item.
I may be wrong, as we don’t have yet installed CERN Search. But I though the sequence was going to be like this
- query against CERN Search returns a JSON
- deserialize the JSON into objects
- we use those objects for HTML interpolation, filling the templates
Using marshmallow for the 2nd step: deserializing JSON docs into objects.
I have to admit I haven’t checked if jinja2 can use directly the json docs to interpolate the HTML templates.
Yes, parsed json data is just python dicts/lists/etc., and you can use them in Jinja like any objects (you can even use . notation to access items).
However, I don’t think we should be showing the data we get back from the search service (it may be stale) but rather query the latest version from the Indico DB based on the ID in the search results.
Huh, that’s new, at least to me. I always thought the idea was to implement an architecture like in the picture.
What would be then the point of issuing 2 queries: one against CERN Search and a second one against the INDICO DB? Why not then directly against the DB? performance?
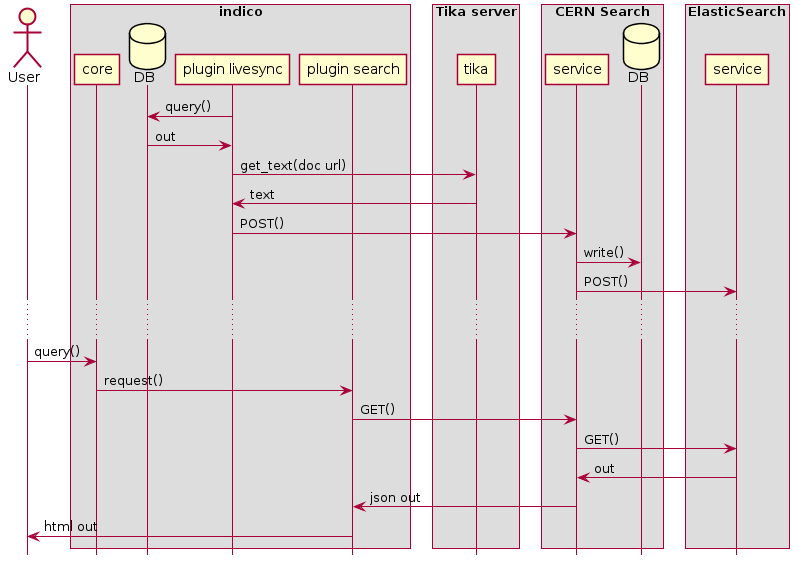
Full text search, including documents. It’s impossible to do that right with a relational DB.
I partially agree with @ThiefMaster, if it’s cheap to get fresh information from the DB, then it may make sense to get it. The important part about querying ElasticSearch is knowing what to display, not how. OTOH, if we’re confident that the data will be relevant almost all the time, then I also don’t understand why we would need to spend the extra milliseconds to go to Postgres.
Don’t want want to do another access check on the Indico side as well? For that we already need to get the object from the DB.
And yeah, I’d say it’s pretty cheap. If you have maybe 100 IDs you can just filter using Event.id.in_(...) to get those…
Anyway, for the first version I don’t think there’s anything wrong with just showing the data directly using the JSON returned by the search service - changing it to query fresh objects from the DB + do access checks again wouldn’t be much work.
It’s true that doing an additional access check wouldn’t hurt. Anyway, let’s discuss that after the first prototype is done, as you suggest.
BTW, which version of INDICO should be working with?
The installation we have at BNL is 2.1.7, which comes with marshmallow 2.x.
Latest version available for pip is 2.1.8, also using marshmallow 2.
IIRC, you upgraded to marshmallow 3 in version 2.2, right?
However, I just tried to build the RPM for 2.2 via distutils (after adding requirements.txt to MANIFEST.in), but it failed [*].
So:
- are we OK working with 2.1.7 or should we upgrade that?
- if we must upgrade to 2.2, how should it be done?
[*]
$ python setup.py bdist_rpm
...
...
+ python setup.py build
/usr/lib64/python2.7/distutils/dist.py:267: UserWarning: Unknown distribution option: 'long_description_content_type'
warnings.warn(msg)
/tmp/indico/venv/lib/python2.7/site-packages/setuptools/dist.py:331: UserWarning: Normalizing '2.2-dev' to '2.2.dev0'
normalized_version,
running build
compiling catalog indico/translations/en_GB/LC_MESSAGES/messages.po to indico/translations/en_GB/LC_MESSAGES/messages.mo
error: indico/translations/es_ES/LC_MESSAGES/messages.po:2640: placeholders are incompatible
error: indico/translations/es_ES/LC_MESSAGES/messages.po:2648: placeholders are incompatible
compiling catalog indico/translations/es_ES/LC_MESSAGES/messages.po to indico/translations/es_ES/LC_MESSAGES/messages.mo
compiling catalog indico/translations/fr_FR/LC_MESSAGES/messages.po to indico/translations/fr_FR/LC_MESSAGES/messages.mo
compiling catalog indico/translations/pt_BR/LC_MESSAGES/messages.po to indico/translations/pt_BR/LC_MESSAGES/messages.mo
2 errors encountered.
error: No such file or directory
error: Bad exit status from /tmp/indico/venv/indico/build/bdist.linux-x86_64/rpm/TMP/rpm-tmp.CG3yWO (%build)
RPM build errors:
Bad exit status from /tmp/indico/venv/indico/build/bdist.linux-x86_64/rpm/TMP/rpm-tmp.CG3yWO (%build)
error: command 'rpmbuild' failed with exit status 1replying to myself… I forgot you don’t install with RPMs, but with pip.
So I found some recipe in my email inbox, and tried it. First I had to install npm and npx.
$ git clone https://github.com/indico/indico
$ cd indico
$ pip install -e .
$ npm install
$ pip install -r requirements.dev.txt
$ mkdir dist
$ python bin/maintenance/build-wheel.py --target-dir=./dist indico
building assets
Error: building assets failed
Object.entries is not a function
Error: running webpack failed
I keep investigating…
outdated nodejs; get something recent like node 10 and it’ll work
Now that we released 2.2, please make sure to use the the 2.2-maintenance branch of Indico and not master anymore.
Using something like nvm would be a good choice, since you can easily change versions regardless of your distro.
Hi,
just for curiosity, I gave it a try to deploy the CERN Search via the docker container. Command “docker-compose up” is failing with this error message:
ERROR: Service 'cern-search-api' failed to build: Error: image webservices/cern-search/cern-search-rest-api/cern-search-rest-api-base:cfe1fe3d1aba819d240acbb6a7bfe79678f82ee5 not found
Is the URL wrong? Or maybe it is a private repo and I need to be added somehow?